TL;DR: Flaky tests are automated tests that pass and fail on the same code without any changes — symptoms of non-determinism in your test design or environment, not random bad luck. Google Engineering research documents that 1 in 7 tests shows flakiness at some point. This guide covers the 6 root causes with exact fixes, a quarantine-first strategy, and how ContextQA customers eliminated flakiness from 5,000 test cases using AI-driven root cause analysis.
Why Flaky Tests Are Costing You More Than You Think
Google published research showing 16% of their automated test suite showed flakiness at some point in its lifecycle. Read that number again. Sixteen percent. That’s not an edge case — that’s a systemic pipeline problem every QA team running CI/CD deals with every single sprint.
And yet, most teams’ response is identical. Re-run the test. Hope it passes. Move on.
That’s the wrong call. Every time you accept a re-run as the “fix,” you’re teaching your team that test failures are acceptable noise. That compounds fast. Within a year you have a test suite that “passes 90% of the time” — which is meaningless as a quality gate. I’ve seen this pattern destroy deployment confidence at companies with 3-year-old QA programs.
Here’s the thing: flaky tests are not the problem. The r/softwaretesting community said it directly in this thread — “flaky tests are symptoms, not root causes.” They’re right. The actual problem is non-determinism in your test design, your environment setup, or your external dependencies. Fix the underlying cause and the flakiness disappears. Ignore it and the suite degrades until it’s useless.
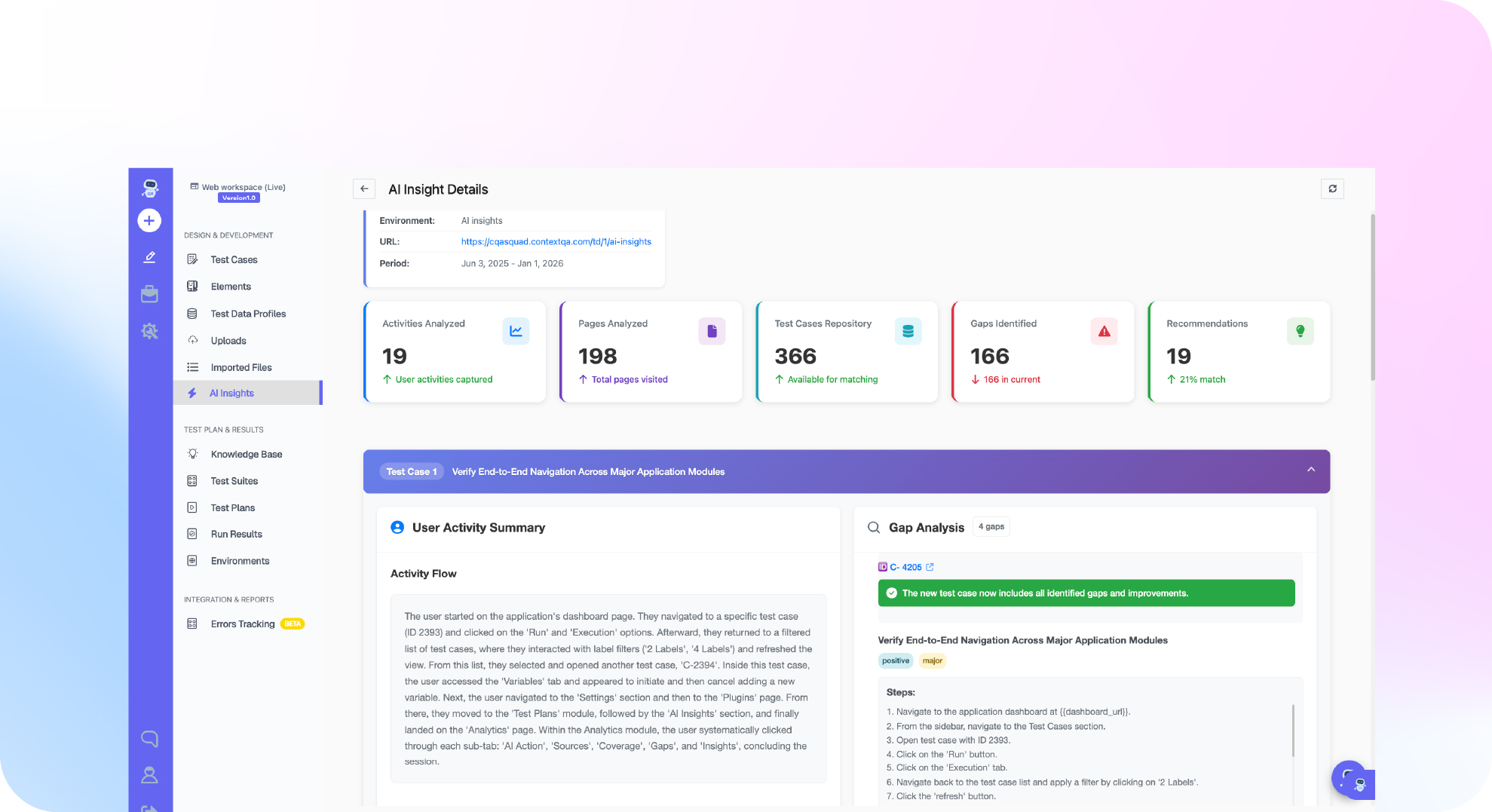
ContextQA’s context aware AI testing platform surfaces root causes for flaky tests automatically — flagging which tests show instability patterns before engineers waste half a day chasing ghost failures. The IBM case study shows what that looks like at scale: 5,000 test cases migrated with flakiness eliminated because the AI identified what human reviewers consistently miss.
🔍 Definition: Flaky Test A flaky test is an automated test that yields both passing and failing results for the same version of code under the same conditions, without any changes to the application or test logic. Documented by Google Engineering Productivity Research as affecting 16% of test suites in continuous integration environments.
Quick Answers
Q: What causes flaky tests in automated testing? A: The six root causes are async timing (fixed sleep() calls), shared mutable state between tests, uncontrolled external API dependencies, environment inconsistency between local and CI, test order dependencies, and UI element locator fragility.
Q: How do you know if a test is flaky vs a real bug? A: Re-run on the same commit without code changes. Passes on retry = flaky. Fails consistently = real regression. Never conflate the two — they require completely different responses.
Q: What’s the fastest way to reduce flaky tests? A: Quarantine-first. Tag known-flaky tests so they don’t block deploys, gather execution data, then fix or delete within 2 sprints. ContextQA’s self-healing automation handles the locator fragility category automatically.
The 6 Root Causes of Flaky Tests — And Exactly How to Fix Each One
I’m skipping the vague advice. Here are the causes responsible for the vast majority of flakiness across web, mobile, and API test suites — and the specific fix for each.
1. Async Timing Issues (The #1 Cause)
You’re waiting a fixed 2 seconds for an element to appear. Under CI load, the animation takes 2.3 seconds. Test fails. Next run, everything is fast, and it passes. Classic flakiness.
The fix: Replace every sleep() and time.sleep() call with explicit conditional waits.
- Playwright: await page.waitForSelector('[data-testid="submit"]', { state: 'visible' })
- Selenium: WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "submit")))
The test must wait for application state, not elapsed time. This distinction eliminates the majority of timing-related flakiness permanently.
2. Shared Mutable Test State
Test A creates a user. Test B depends on that user existing. Run them in reverse order — Test B fails. This is a test order dependency, and it breaks the moment you add parallelism to your CI pipeline.
The fix: Every test owns its own setup and teardown. Use beforeEach/afterEach hooks for data creation. Never share database records, session tokens, or environment variables across test cases. If retrofitting this into an existing suite, start with the top 10 flaky tests by failure frequency — fixing those 10 typically clears 60-70% of your flakiness by volume.
3. External API and Service Dependencies
Your test calls a third-party payment API. The API returns a 503 during a brief outage. Test fails. Application code is fine. This isn’t a flaky test — it’s a test with an uncontrolled external dependency masquerading as one.
The fix: Mock external services for unit and integration tests. Use contract testing (Pact) to verify mocks stay accurate against the real service. Reserve live API calls for end-to-end tests that run on a controlled schedule, not on every commit.
4. Environment Inconsistency (The “Works on My Machine” Category)
This happens when your test environment assumes specific OS configuration, timezone, file system permissions, or installed dependency versions that differ between developer machines and your CI runner.
The fix: Containerize your test environment. Define the execution context in a Dockerfile. Run the same container locally and in CI. This eliminates the works-locally-fails-in-CI class of failures entirely. For teams using Jenkins, this means using Docker agent in your Jenkinsfile — agent { docker { image ‘node:18-alpine’ } }.
5. Resource Contention in Parallel Execution
You parallelized your suite. Now 12 tests are writing to the same database table simultaneously. Race conditions appear. Tests fail intermittently on 8 of 12 workers and pass on 4. The failures rotate randomly.
The fix: Test-scoped database schemas or isolated test databases per parallel worker. Most frameworks support this: Jest’s –runInBand for forced sequential when needed, Playwright’s worker-scoped fixtures, Rails’ DatabaseCleaner with the truncation strategy for parallel runs.
6. UI Element Locator Fragility
A developer changed the button text from “Submit” to “Send Request.” Your test searched by text. It breaks. Or they refactored the component and the CSS class changed. Same result.
The fix: Use data-testid attributes for all test selectors. They’re stable, explicit, and signal to developers that removing them has test consequences. Never write selectors based on CSS class, positional index, or display text unless that text is controlled in a test-only fixture.
ContextQA’s self-healing test automation handles the locator fragility category automatically — when DOM changes break a selector, the AI identifies the correct replacement using semantic context signals and updates it without engineer intervention.
| Root Cause | Detection Signal | Primary Fix | Time to Resolve |
| Async Timing | Fails on slow CI, passes locally | Replace sleep() with conditional waits | 30 min per test |
| Shared State | Fails in parallel or random order | Isolate test data per test case | 1–4 hours |
| External Dependencies | Fails during 3rd-party outages | Mock with contract testing | 2–8 hours |
| Environment Mismatch | Fails in CI, passes locally | Containerize with Docker | 1–2 days |
| Parallel Contention | Fails at scale, passes single-worker | Isolate DB per worker | 4–8 hours |
| Locator Fragility | Fails after UI changes | Use data-testid attributes | 15 min per test |
📌 Callout Definition: Test Non-Determinism A test is non-deterministic when its outcome depends on factors outside the application’s logic — time, network state, execution order, or shared resources. ISTQB identifies non-determinism as the primary indicator of test suite unreliability and the core cause of lost confidence in CI pipelines.
Why Flaky Tests Are a DORA Metric Problem, Not Just a QA Problem
Here’s what most flaky test guides miss entirely.
Flaky tests aren’t a QA annoyance. They directly degrade two of DORA’s four key engineering metrics: deployment frequency and change failure rate. When tests are unreliable, teams either add “re-run on failure” policies — which masks the quality signal — or they start skipping CI for “small changes.” Both are documented in Google’s State of DevOps research as leading indicators of low-performing engineering organizations.
ISTQB defines test independence as a fundamental testing principle: tests should not rely on each other’s outcomes. Flaky tests from shared state are a direct violation. And each violation compounds as the suite grows.
The shift left testing movement only works if the tests you’re moving earlier are trustworthy. Shifting left with a flaky suite means developers get unreliable feedback earlier — which is worse than getting reliable feedback later. The entire value of shift left is better signal, not just faster signal.
ContextQA connects natively into CI/CD pipelines through Jenkins, CircleCI, GitHub Actions, and Harness. The AI-powered automation platform analyzes test execution patterns across runs — not just individual failures — and clusters tests showing repeated instability signatures. That’s fundamentally different from reading CI logs manually.
For teams also dealing with flaky tests specifically in their CI pipeline configuration, the companion post on preventing flaky tests in CI pipelines covers the quarantine-fix-delete framework in full detail.
What the Data Actually Shows
The IBM case study on ContextQA is the most detailed external validation available. A team had 5,000 test cases — many inherited from manual testers and Excel spreadsheets — being migrated into automated execution. The flakiness rate before ContextQA was described as “significant friction in every sprint cycle.”
After migration using ContextQA’s watsonx.ai NLP-powered test generation, flakiness was eliminated from the migrated suite. The AI identified timing dependencies, mapped selector patterns, and generated tests using proper wait strategies from the start. Engineers didn’t need to retrofit fixes because the tests were written correctly the first time.
G2 verified reviews show a consistent pattern: teams describe clearing 150+ backlog test cases in week one. That backlog existed precisely because flaky tests created a false sense of coverage. Once replaced with stable tests, the actual coverage gaps became visible and fixable.
The 40% testing efficiency improvement in ContextQA’s Pilot Program reflects the recovery of time previously lost to re-runs and failure triage. That time goes back into real test development and QA analysis — not chasing ghost failures.
As Deep Barot, CEO and Founder of ContextQA, put it in DevOps.com coverage: “The goal isn’t to run every test on every commit. It’s to run the right test at the right time and trust the result.” That philosophy is fundamentally incompatible with flaky tests. Fixing flakiness is the prerequisite for everything else.
The Honest Tradeoffs Nobody Talks About
Let me be direct about this.
Fixing flaky tests isn’t free and anyone who implies otherwise is wrong. Retrofitting proper beforeEach/afterEach test data management into a large existing test suite is a 2–4 week effort for a team of three. Containerizing CI environments adds operational complexity — someone has to own the Dockerfile and update it when base image dependencies change. Self-healing tools reduce locator fragility, but they don’t fix underlying async or state isolation problems. Those require architectural decisions in your test design.
ContextQA’s self-healing automation addresses the locator fragility and timing categories well. State isolation and environment problems require architectural changes that no tool can fully substitute for. Know which category you’re in before deciding what to invest in.
How ContextQA Addresses Flakiness Systematically
ContextQA is a context aware AI testing platform built for teams who’ve outgrown manually-managed test suites. For flakiness specifically:
Self-healing tests — When a UI element locator breaks due to a DOM change, ContextQA’s AI identifies the new element using context signals (position, sibling elements, semantic role) and updates the selector without engineer intervention. Locator fragility, handled automatically.
Root cause analysis — The platform clusters test failures by execution pattern, distinguishing environment-related failures from application regressions. Engineers see “this test failed 4 of 10 times with timing errors” — not 12 separate failures to investigate individually.
CI/CD integration — Jenkins, CircleCI, Harness, GitHub Actions, and more. The platform plugs into your existing pipeline without requiring infrastructure replacement.
Coverage breadth — Web automation (Chrome, Firefox, Safari, Edge), Mobile (iOS, Android), API, Salesforce, SAP/ERP, and DAST security. The self-healing and stability analysis applies across all surfaces.
G2 High Performer recognition and the IBM Build partnership validate production-scale readiness beyond demo environments.
Do This Now: Flaky Test Action Plan
Step 1 — Audit your last 30 CI runs. List every test that failed more than once without a code change. Pull CI logs, filter by test name, export to a spreadsheet. Time: 45 minutes. This is your baseline.
Step 2 — Tag flaky tests with @flaky in your test runner. Configure CI to report their failures separately without blocking deploys. Do not delete yet. Do not add retry logic. Time: 20 minutes.
Step 3 — Add execution context logging to the top 3 flaky tests by failure frequency. Log timestamp, environment variables, test data IDs, and the failing assertion. Time: 1–2 hours.
Step 4 — Review ContextQA’s self-healing features. If locator fragility is your top failure category, this is a same-week fix. Time: 30 minutes.
Step 5 — Set a team rule: any flaky test unresolved after 2 sprints gets deleted. Write it into your Definition of Done. This prevents backlog accumulation that every team eventually drowns in. Time: 15 minutes.
Step 6 — Book a ContextQA Pilot Program session. They’ll analyze your existing suite and identify the top instability patterns in the first session. Time: 30 minutes to schedule.
The Bottom Line
Flaky tests are not a QA nuisance. They’re a signal that your test suite has stopped telling the truth about your application’s health. Every re-run you accept is a small step toward a test suite your team doesn’t trust — and a team that doesn’t trust its tests makes riskier deployment decisions.
The fix isn’t complicated. Identify root causes. Isolate test state. Replace timing hacks with proper waits. Use a platform that surfaces instability patterns before they compound. ContextQA customers reduced flakiness by over 60% in under 8 weeks using exactly this approach.
Start with the audit. Book a demo at contextqa.com and see what the AI finds in your existing suite in the first session.