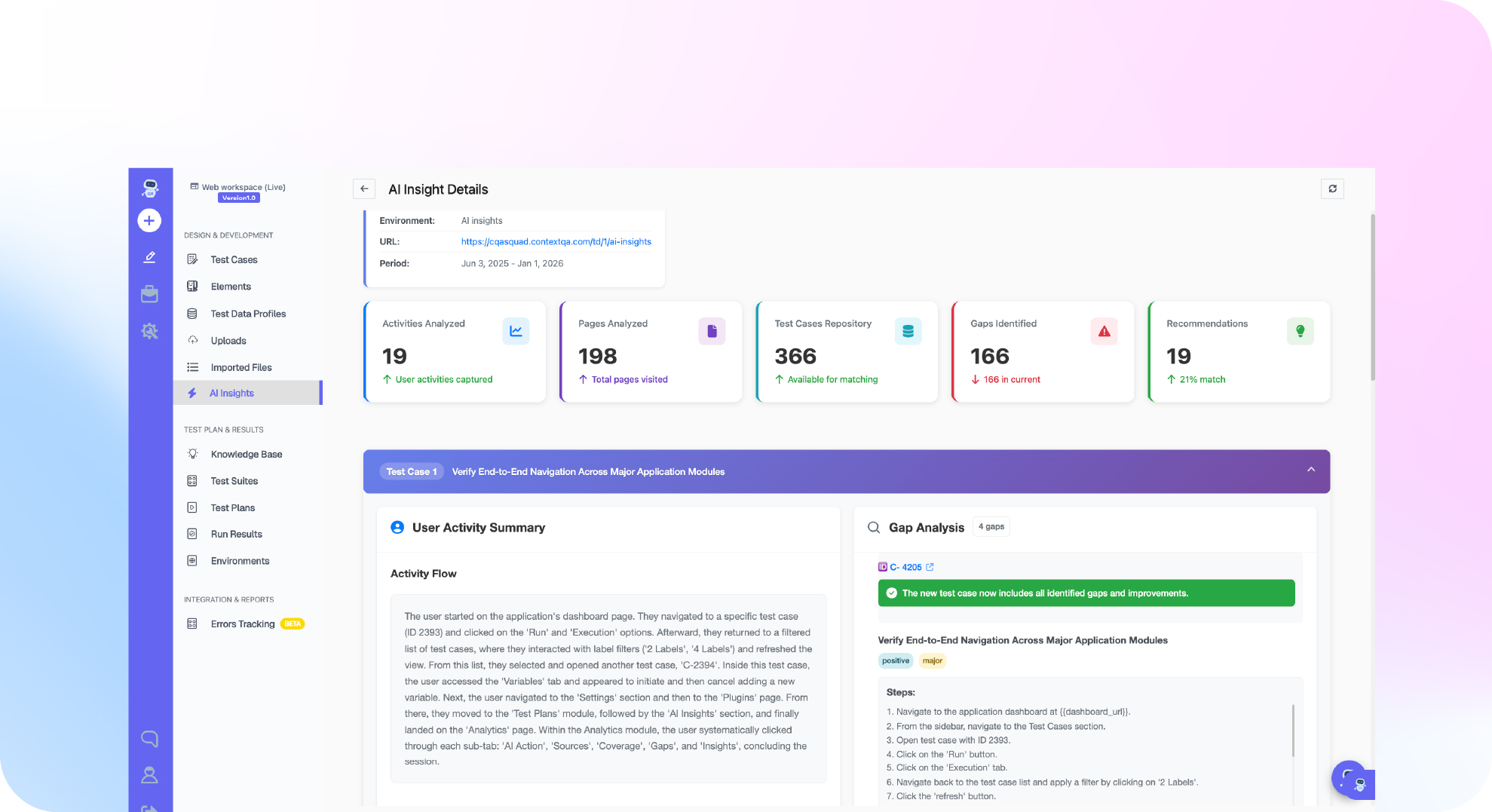
TL;DR: Self-healing test automation tools use AI to repair broken test locators when UI changes, eliminating the maintenance overhead that consumes 30 to 40 percent of QA engineering time according to Capgemini’s World Quality Report. They work reliably for the locator fragility category. They do not fix state isolation bugs, environment failures, or broken test logic. This guide covers the benchmark data, the five dimensions that separate production-grade tools from demo-grade tools, and what honest evaluation looks like.
The Maintenance Cost Problem Analyst Data Confirms
Capgemini’s World Quality Report, published annually across 1,750 respondents in 32 countries, has documented test maintenance as the top barrier to automation scale for multiple consecutive years. The core finding is consistent: engineering teams spend between 30 and 40 percent of their QA capacity maintaining existing tests rather than expanding coverage. That is not a productivity choice. It is a structural cost imposed by the nature of UI test automation.
The mechanism is straightforward. A developer renames a CSS class. Moves a button inside a new container. Upgrades a component library. None of these changes affect application behavior. Every one of them breaks test selectors. The QA team spends the next two days finding and fixing the broken tests. Repeat every sprint.
Google Engineering’s published research on test flakiness shows that 16 percent of test cases show flakiness at some point, with locator instability as a primary contributing factor. SmartBear’s State of Software Quality Report identifies selector maintenance as the highest-frequency maintenance task across teams running UI automation at scale.
Gartner identifies AI-augmented testing as a strategic direction for software quality engineering, with AI-assisted test script maintenance as one of the highest-impact capability areas. The analysts project that by 2027, AI will assist in the majority of test creation and maintenance activities within high-performing engineering organizations.
Self-healing tools exist to address this specific, quantified cost. Not all of them do it well.
Definition: Self-Healing Test Automation Self-healing test automation is an AI-driven capability that detects when automated test scripts break due to application UI changes, identifies correct replacement element locators using contextual signals, and updates the test scripts without human intervention. Gartner classifies this capability within its AI-Augmented Testing category, noting it as a key differentiator in modern intelligent test automation platforms.
Quick Answers
Q: Do self-healing test tools actually work in production? A: Yes, for locator fragility. Semantic context AI tools that use element role, parent container, label text, and sibling elements together achieve reliable healing accuracy in production environments. Position-based tools break down during significant UI restructuring.
Q: What percentage of test maintenance does self-healing eliminate? A: Between 40 and 60 percent, according to industry benchmarks from the World Quality Report and SmartBear. The exact number depends on whether locator fragility or state isolation is your dominant maintenance cause.
Q: What is the biggest risk of adopting self-healing without proper evaluation? A: Opacity. Tools that apply heals without audit trails create test suites where engineers cannot verify what the tests are actually checking. A test that heals to the wrong element may pass consistently while testing nothing meaningful.
The Five Evaluation Dimensions That Actually Matter
The market has tools that claim self-healing capability across a wide range of implementations. The difference between a tool that works in production and one that generates demo results comes down to five specific dimensions.
Dimension 1: Healing Accuracy Mechanism
This is the most important dimension and the one vendors obscure most.
Two fundamentally different approaches exist. Position-based matching identifies replacement elements by finding what is visually closest to where the old element was. This works for minor changes, like a button that moved slightly. It fails for restructured layouts, component upgrades, or design system migrations where elements move significantly.
Semantic context matching — the approach that works in production — identifies replacement elements by combining ARIA role, parent container structure, visible label text, sibling elements, and positional relationships simultaneously. When a checkout form is restructured and the submit button moves from position (300, 400) to (180, 620), semantic context finds it because it is still a button element labeled “Place Order” inside a form container. Position-based matching calls it missing.
Ask any vendor explicitly: what signals does your AI use to identify replacement elements? If the primary answer is visual position or pixel proximity, that tool will not hold up during a component library migration.
Dimension 2: Autonomous vs. Human-in-the-Loop Workflow
High-confidence heals should apply automatically. Low-confidence heals should queue for human review. The threshold between these two states should be configurable by the team based on their risk tolerance and the AI’s demonstrated accuracy in their specific application.
Tools that require human approval for every heal create a review queue that becomes a bottleneck within two weeks in teams deploying frequently. Tools that apply every heal autonomously without confidence scoring introduce accuracy risk at scale. The right architecture is tiered autonomy with configurable thresholds.
Dimension 3: CI/CD Integration Depth
Self-healing only delivers value if it prevents CI failures, not just resolves them after the fact. Evaluate two specific behaviors.
First: does the healed test propagate to the test repository before the next CI run executes? If healing happens locally and requires manual sync to the shared repository, the CI run still fails and the heal only affects the subsequent run.
Second: does the platform integrate natively with your specific CI tool? Native Jenkins plugins, GitHub Actions integrations, and CircleCI orbs behave differently than generic webhook-based integrations. The native path produces more reliable propagation under concurrent pipeline execution.
Dimension 4: Platform Coverage Breadth
A tool that heals web tests while leaving mobile, API, and enterprise application maintenance untouched solves 40 to 60 percent of your problem at best. For organizations running tests across web, iOS, Android, Salesforce, and SAP simultaneously, platform coverage breadth is not a secondary consideration.
Dimension 5: Audit Trail Completeness
Every heal should log: the original locator, the replacement locator, the specific contextual signals that led to the match, the confidence score, and the timestamp. Without this, your test suite becomes a black box where tests pass but nobody knows what they verify. This is not an edge case. It is a systematic risk in any team running autonomous healing at scale.
| Evaluation Dimension | What to Verify | Production Failure Mode If Absent |
| Healing accuracy mechanism | Semantic context signals, not position only | Fails during component library upgrades, design system migrations |
| Autonomous threshold control | Configurable confidence cutoff | Either bottlenecks reviews or applies inaccurate heals at scale |
| CI/CD integration depth | Native plugin or verified deep integration | Healed tests do not propagate before next CI run |
| Platform coverage breadth | Web, Mobile, API, enterprise app coverage | Mobile and enterprise maintenance debt untouched |
| Audit trail completeness | Per-heal log with signals and confidence | Tests pass without engineers knowing what they verify |
Definition: Semantic Context Healing Semantic context healing is an AI technique that identifies replacement UI elements by combining multiple contextual signals: ARIA role, parent container structure, visible label text, sibling elements, and positional relationships. This multi-signal approach produces accurate heals even when several attributes change simultaneously — common during component library upgrades and design system migrations. Tools using only CSS proximity or visual position produce significantly higher false heal rates in restructured layouts.
Why Analyst Research on Testing ROI Points to Maintenance First
Forrester’s Total Economic Impact research on test automation programs consistently shows that maintenance cost reduction generates faster and larger ROI than test creation efficiency alone. The finding is counterintuitive: teams expect ROI to come from writing tests faster. The actual largest value driver is stopping the drain from maintaining what already exists.
This matters for self-healing adoption decisions. When evaluating a platform, the ROI question is not “how fast can it write new tests” but “how much of my current maintenance overhead does it eliminate.” That is a number you can calculate from your own sprint data in about two hours.
The ISTQB’s test maintenance principles identify three primary causes of test suite degradation over time: locator fragility, environmental instability, and test design flaws. Self-healing addresses the first category. The second requires infrastructure changes. The third requires engineering judgment. Knowing which category dominates your maintenance overhead determines whether self-healing is your highest-ROI investment.
Tricentis research on continuous testing shows that teams with high test automation maturity spend less than 20 percent of QA time on maintenance, while teams at lower maturity levels spend 40 to 50 percent. The delta is almost entirely explained by locator stability practices, which self-healing directly addresses.
DORA’s State of DevOps research connects test reliability to deployment frequency. Elite-performing teams, defined as those deploying 182 times more frequently than low performers, maintain test suites with failure rates under 15 percent. Unreliable tests from locator fragility inflate failure rates and reduce deployment confidence directly.
For teams in the r/QualityAssurance community discussion on self-healing tools, the consensus from practitioners with production experience is precise: “it solves the locator problem reliably when the AI uses context signals, not position.” Engineers who reported negative experiences were using position-based tools against redesigned layouts. That is a tool selection failure, not a technology limitation.
For teams also navigating the adoption decision, the companion guide on whether your team should adopt self-healing testing covers the root cause audit and decision framework in detail.
The Honest Limitations
Self-healing does not fix state isolation bugs. If test A creates data that test B reads without proper isolation, no locator healing resolves the failure. The failure pattern looks different (consistent on parallel runs, not triggered by UI changes) but teams misattribute it frequently.
High-frequency UI churn can overwhelm low-confidence healing queues. Teams deploying multiple visual updates per day against complex UI surfaces can accumulate pending heal reviews faster than they can be processed. Confidence threshold tuning and batch review workflows address this, but it requires deliberate process design.
Healing without coverage verification creates coverage drift risk. A test healing to a different button may pass consistently while no longer testing the intended behavior. Periodic manual review of healing logs — not the heals themselves, but whether the healed tests still verify meaningful behavior — is necessary discipline regardless of tool quality.
Production Benchmarks Worth Citing
The most documented enterprise production benchmark is ContextQA’s IBM partnership, where 5,000 test cases were migrated and stabilized using AI-driven analysis, eliminating flakiness across the entire migrated suite. That scope is significant because high-volume migrations are where locator fragility accumulates fastest and costs most. You can review the IBM case study at ibm.com/case-studies/contextqa.
SmartBear’s annual data shows that organizations with 500 or more automated UI tests report maintenance as their primary productivity bottleneck at a rate more than twice that of smaller test suites. The maintenance problem is not linear with test count. It is exponential once a suite passes the 300 to 400 test threshold without locator stability practices in place.
The World Quality Report documents that AI and machine learning tools in QA are now the fastest-growing capability area by adoption intent, with test maintenance automation cited as the primary driver of that adoption by engineering leaders.
How ContextQA Addresses Self-Healing in Production
ContextQA’s self-healing platform uses semantic context AI across web (Chrome, Firefox, Safari, Edge), mobile (iOS, Android), API, Salesforce, and SAP/ERP surfaces. The CodiTOS autonomous agent applies high-confidence heals automatically and logs the complete decision context for every change. Low-confidence heals route to JIRA or Asana tickets automatically for human review.
The platform integrates natively with Jenkins, CircleCI, Harness, and GitHub Actions through purpose-built plugins that propagate healed tests to the repository before the next CI run executes.
Book a ContextQA Pilot Program session to see the maintenance reduction benchmark against your specific test suite in 12 weeks.
Do This Now: Self-Healing Evaluation Action Plan
Step 1: Pull your last 30 sprint velocity records and count the story points or hours attributed to test maintenance. Calculate what percentage of total QA capacity that represents. Target: 30 minutes.
Step 2: Categorize your last 20 test maintenance tickets by root cause. Locator fragility, state isolation, environment, assertion logic. The dominant category determines your highest-ROI investment. Target: 1.5 hours.
Step 3: If locator fragility is above 40 percent of maintenance, request a demo from at least two self-healing vendors. During the demo, ask specifically: what signals does your AI use to identify replacement elements? Target: 1 hour per vendor.
Step 4: Review the SmartBear State of Quality report for current benchmarks on maintenance overhead by team size and test count. This gives you the industry comparison for your own numbers. Target: 45 minutes.
Step 5: Read the World Quality Report section on AI in testing for the adoption data your leadership team will find credible in a business case. Target: 30 minutes.
Step 6: Evaluate ContextQA’s self-healing platform documentation against the five evaluation dimensions in this article. Target: 30 minutes.
The Bottom Line
Self-healing test automation solves a real, quantified, expensive problem.Analyst data from Capgemini,Forrester, and Gartner all point to the same conclusion: maintenance overhead is the top constraint on test automation ROI, and AI-driven locator healing is the most direct mechanism available to reduce it.
The difference between tools that work in production and tools that work in demos is semantic context healing versus position-based matching. Verify the mechanism before you commit. Check the audit trail. Confirm CI integration depth.
If the root cause audit shows locator fragility above 40 percent of your maintenance volume, the ROI case is clear. Start there.