TL;DR: Most test automation RFP templates were written before AI agents existed, and it shows. They score integrations and support SLAs in detail, then miss the four criteria that actually separate AI testing vendors: guardrail testing, tool-call validation, model-drift policy, and a self-healing rate measured live on your application. This guide gives you the full test automation RFP structure, a 100-point weighted scorecard you can copy, and the exact questions that expose weak vendors before the contract does.
Last updated: July 4, 2026
Quick answers
What should a test automation RFP include? Six sections: your current stack and pain points, functional requirements tied to your real applications, AI-specific evaluation criteria, security and compliance requirements, a weighted scoring rubric agreed before responses arrive, and a structured bake-off stage for the finalists.
How do you evaluate test automation vendors? Score every response against a weighted rubric written before you read a single proposal. Weight what differentiates vendors on your stack: enterprise app coverage, AI agent test depth, maintenance model, and test portability. Then verify the top two claims in a live trial, because slideware and software diverge.
How long does a test automation RFP take? Six to ten weeks end to end: two weeks to write requirements and the rubric, three weeks for vendor responses, one week to score, and two to four weeks for the finalist bake-off. Teams that skip the bake-off routinely sign the best writer instead of the best tool.

What should a test automation RFP include?
A working test automation RFP has six sections, and the order matters because each one narrows the field for the next.
1. Your context. Applications under test, technology stack, release cadence, team size and skills, and the specific pain that triggered the search. Vendors write better responses against real context, and vague RFPs get boilerplate back.
2. Functional requirements. Name your actual applications. If your revenue flows run through SAP, Salesforce, or a 15-year-old internal portal, say so explicitly and require vendors to state coverage in writing. Generic “web testing” requirements produce generic answers that hide the gaps.
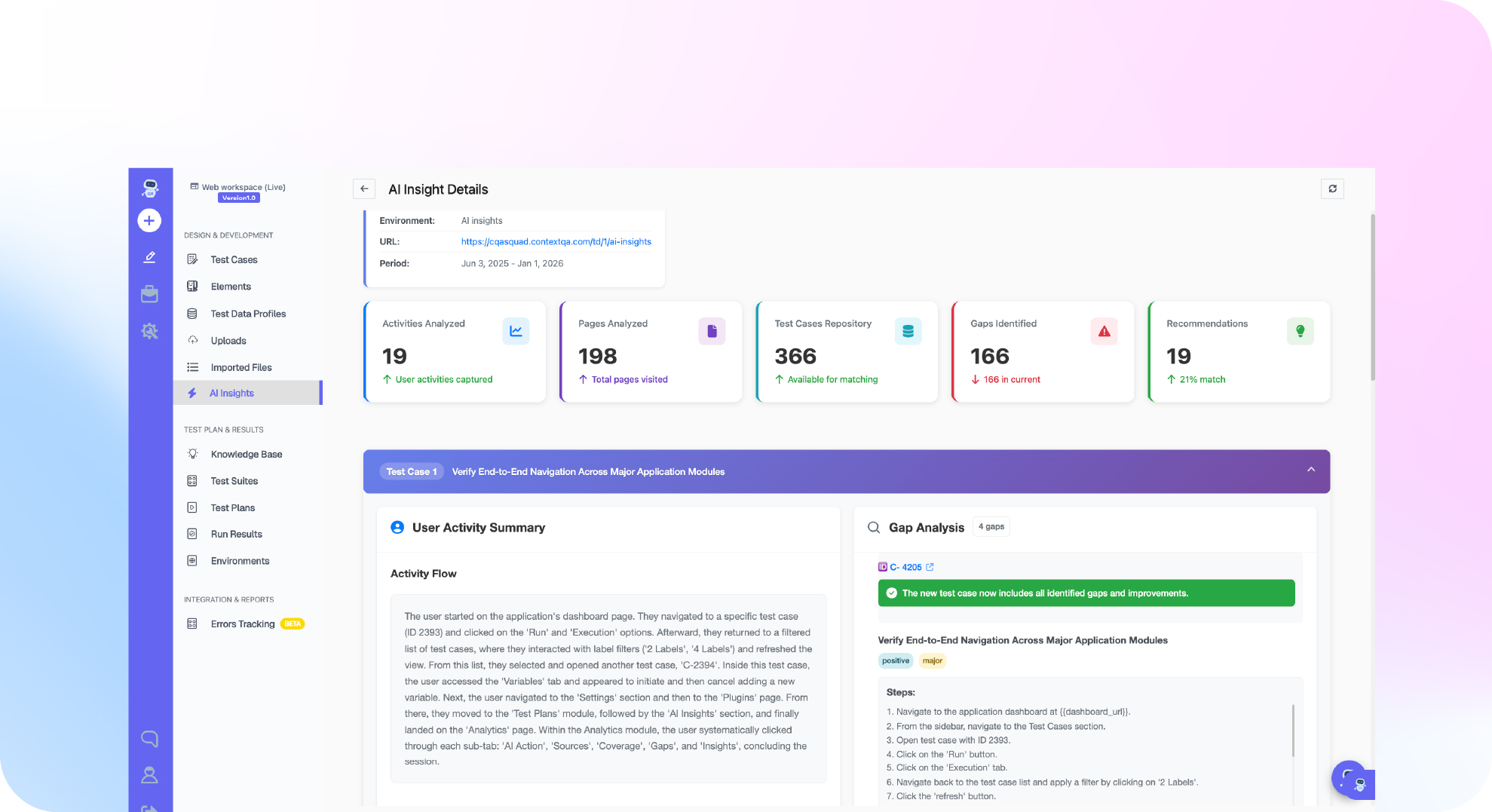
3. AI evaluation criteria. The section most templates miss entirely, covered in depth below.
4. Security and compliance. SOC 2 Type II reports, SSO, role-based access, data residency, and how customer data is used in model training. The AICPA’s SOC framework is the reference standard here; ask for the actual report, not the badge.
5. The scoring rubric. Written and agreed before responses arrive. Procurement platform Responsive’s published guidance describes typical enterprise weightings that put pricing near 40 percent of the score. For test automation that is a mistake: a cheap tool your team abandons costs more than an expensive one they use. Weight capability on your stack first.
6. The bake-off. A structured trial for the top two vendors, on your applications, with exit criteria. The RFP finds the shortlist; the bake-off finds the tool.
What evaluation criteria do AI testing vendors actually differ on?
Every serious vendor now claims AI. The claims converge; the implementations do not. Four criteria separate the field, and standard test automation RFP templates ask about none of them.
Guardrail and hallucination testing. If you are deploying AI agents or LLM features, your testing platform must probe safety boundaries: PII disclosure, policy violations, prompt injection, unauthorized actions. Ask each vendor to demonstrate a guardrail test against a live agent, not describe one.
Tool-call validation. Agents act through function calls. A testing platform that only reads final text output misses the wrong-tool, wrong-argument failures that cause real damage. Ask how the platform asserts on tool calls specifically.
Model-drift regression. Model upgrades change agent behavior without any code change. Ask what the vendor re-runs when an underlying model updates, and who pays for that compute.
Self-healing rate, measured live. Every vendor claims self-healing maintenance. The honest way to evaluate self-healing is a live measurement: ship a UI change to your own application during the trial and count which tests survive untouched. Slides do not survive contact with your DOM.
What questions should you ask test automation vendors?
Beyond the scorecard, seven questions produce the most revealing answers in a test automation RFP process. The pattern to watch: strong vendors answer with numbers and demonstrations, weak vendors answer with adjectives and roadmaps.
1. “Show us a test being created on OUR application, live, during this call.” Time it. Minutes is an answer; a follow-up services proposal is also an answer.
2. “What happens to our tests if we leave?” The only good answer is exportable, runnable code. Test portability is the difference between a vendor and a hostage negotiation at renewal.
3. “What is your measured self-healing rate on customer applications, and how do you calculate it?”
4. “Which enterprise systems do you test natively?” Then name yours and ask for a reference customer on the same stack.
5. “How do you test AI agents beyond the chat window?” Listen for tool calls, guardrails, and drift. Our AI agent testing page shows what depth looks like here.
6. “What does the first 90 days cost, all in: licenses, onboarding, training, and infrastructure?” Insist on a number in writing. Vendors who defer pricing to the final round are negotiating, not answering.
7. “Who does the work during the trial, your engineers or ours?” If vendor engineers build the pilot, you are evaluating their staff, not their product.
How do you weight and score RFP responses?
Use the 100-point scorecard above, and enforce three process rules that matter more than the exact weights.
Score independently, then reconcile. Have each stakeholder score alone before the group meets. Group-first scoring converges on the loudest voice, and the loudest voice is rarely the person who will maintain the tests.
Kill on floors, not averages. Set minimum scores on the top four criteria. A vendor scoring 2 of 20 on enterprise app coverage is disqualified even with a 90 total, because averages hide fatal gaps. Our AI testing platform buyer’s guide covers the 12 questions behind those floors.
Make finalists prove the two highest-weighted claims live. Whatever scored highest on paper gets verified in the bake-off. Paper scores select finalists; only demonstrations select winners.
How much does running a test automation RFP cost?
A real number teams rarely calculate: a six-to-ten-week test automation RFP consumes roughly 120 to 200 internal hours across QA leadership, procurement, security review, and engineering evaluators. At a blended $75 per hour, that is $9,000 to $15,000 of internal cost before any license is signed. Two implications follow.
First, do not run a full RFP for a small team’s tooling decision; a two-week structured trial answers the same question for a fraction of the cost. Second, if you do run one, protect the investment by refusing to skip the bake-off, because the RFP’s entire value concentrates in the final verification step. Skipping it converts $15,000 of diligence into a coin flip weighted toward the best proposal writer. The ROI math on test automation only materializes when the tool actually fits.
Which mistakes ruin test automation RFPs?
Writing requirements from vendor websites. If your requirements list reads like a feature matrix, vendors will match it word for word. Write requirements from your failures instead: the last five releases that broke, and what would have caught them.
Letting the incumbent write the spec. Requirements copied from your current tool’s capabilities guarantee you buy your current tool again with a different logo.
Scoring demos on rehearsed apps. Vendor demo applications are chosen because they demo well. Your test automation RFP should require every demonstration to run on your application or a fresh clone of it.
Ignoring the security review until the end. A vendor who fails SOC 2 review in week nine wastes nine weeks. Frameworks like the Cloud Security Alliance’s AI safety work give your security team a vocabulary for evaluating AI vendors early, in parallel with the functional scoring.
No agreed rubric before responses arrive. Scoring criteria written after reading proposals get bent, consciously or not, toward a favorite. Locking the rubric first is the single most consequential process decision in the entire evaluation, and it costs nothing.
How is an AI testing RFP different from a traditional one?
Three structural differences, beyond the criteria themselves.
The demo requirement moves up front. Traditional tools varied in degree; AI-native tools vary in kind, and the fastest way to sort real capability from wrapper marketing is a live build on your application in the first vendor call, not the last. Teams that restructure the test automation RFP around an early live-build round report cutting their shortlist in half before reading a single written response.
Data handling becomes a first-class section. AI platforms see your application, your test data, and sometimes your production traffic. The RFP must ask where that data goes, whether it trains shared models, how long it is retained, and what happens to it at contract end. A vendor without crisp written answers here fails procurement eventually; better it fails in week two than week nine.
Roadmap weight drops to zero. In a market moving this fast, features promised for next quarter are worth nothing in a scoring rubric. Score what demonstrably works today on your stack; treat every roadmap slide as fiction that occasionally comes true.
What does the RFP timeline look like week by week?
Weeks 1 to 2: requirements and rubric. Write context, requirements from your last five escaped defects, the weighted scorecard, and security questions. Get the rubric signed off by every stakeholder who will later score.
Week 3: issue and clarify. Send to 5 to 8 vendors. Run one clarification call per vendor, 30 minutes, same questions to all so the answers stay comparable.
Weeks 4 to 6: responses and live builds. While vendors write, run the live-build sessions. By the time written responses arrive, you already know who can actually do the work; the documents then confirm pricing, security, and support rather than deciding the ranking alone.
Week 7: independent scoring, then reconciliation. Individual scores first, group session second, floors enforced, top two selected.
Weeks 8 to 10: the bake-off. Both finalists, same ten flows, your team driving, exit criteria from the scorecard. The winner gets a contract; the runner-up gets honest feedback and a genuine second-place file for renewal season, because incumbent alternatives are negotiating assets.
A copy-paste test automation RFP outline
Steal this structure directly into your document:
Section 1, Company context: product, stack, release cadence, team profile, current tooling, the failure that triggered this search. Section 2, Scope: applications in scope with technology detail, environments, integrations required (CI, test management, ticketing). Section 3, Functional requirements: authoring model, execution and parallelization, coverage across web, mobile, API, and enterprise apps, reporting.
Section 4, AI capabilities: the four differentiators above, each with “demonstrate, not describe” noted. Section 5, Security and legal: SOC 2 report request, data handling, SSO, DPA terms. Section 6, Commercial: first-year all-in pricing, renewal mechanics, exit terms including data and test export. Section 7, Process: your timeline, scoring rubric shared openly, bake-off structure and criteria. Sharing the rubric with vendors is deliberate: it tells the strong ones exactly where to prove themselves and gives the weak ones nowhere to hide.
Which red flags in RFP responses predict bad vendors?
After the scorecard is tallied, read the responses once more for pattern recognition. Five signals reliably predict a painful year two.
Adjective density. Count the claims with no number attached. A response that says “dramatically reduces maintenance” instead of “our measured self-healing rate across customer suites is X percent” is telling you the number does not flatter them. The ratio of adjectives to figures is the fastest quality proxy in the whole stack of documents.
Answering a different question. Weak vendors answer the question they wish you asked. You ask about SAP coverage, they answer about browser coverage. In a test automation RFP, every dodged question should be re-asked once in writing; a second dodge is a no.
Services dressed as software. If the implementation plan quietly includes weeks of vendor professional services to reach first value, the product needs those services to function. Price the services into the comparison and re-rank; the ranking usually changes.
The compliance shrug. “SOC 2 in progress” has been in progress at some vendors for three years. In progress is a no for regulated buyers, and a discount lever for everyone else.
Reference stalling. Strong vendors produce same-stack references within days. Two weeks of scheduling friction around references is itself the reference.
How should you run vendor reference calls?
References are the least-used, highest-signal step in the entire test automation RFP process, and they are almost always run badly: a friendly 20-minute call with a customer the vendor picked, hearing what the vendor rehearsed. Fix it with structure.
Ask for a same-stack reference, not a logo. A famous brand testing a React marketing site tells you nothing about your SAP estate. The request that matters: “a customer at similar scale, on our technology mix, live for at least a year.”
Interview the practitioner, not the buyer. The person who approved the purchase defends the purchase. Ask to speak with the engineer who works in the tool daily; their hesitations are your year-two preview.
Ask the three questions that produce honesty. “What broke in your first ninety days?” Everything breaks somewhere; a reference who says nothing broke is coached. “What do you still do manually that you expected the tool to handle?” This surfaces the marketing-to-reality gap directly. “If you were negotiating again, what would you change in the contract?” This one routinely pays for the entire RFP process in a single sentence about renewal terms or usage true-ups.
Weight silence correctly. A vendor unable to produce any same-stack practitioner reference is not early-stage and unlucky; on your stack, they are unproven, and your scorecard’s enterprise coverage row should say so.
More questions teams ask about test automation RFPs
Should you disclose budget in the RFP? Disclose a range, not a number. A range filters out vendors who were never in your bracket and saves everyone three weeks, while keeping negotiating room. Omitting budget entirely invites responses spread across a 10x price spectrum, which makes scoring noise, not signal.
How many vendors should receive a test automation RFP? Five to eight. Fewer than five and you have pre-decided; more than eight and the clarification calls alone eat the calendar. The live-build round then cuts to three or four written responses that deserve full scoring, and two finalists for the bake-off.
Can a small team skip the RFP entirely? Yes, and most should. Below roughly 20 engineers, the structured two-week trial with written exit criteria delivers the same decision quality at a tenth of the process cost. The full test automation RFP earns its overhead when multiple teams, procurement, and security all hold veto power.
Who makes the final call when scores disagree with instincts? The person who owns the production consequence, which is usually the QA or engineering lead, not procurement. Scores structure the argument; they do not replace it. When instinct and scorecard diverge sharply, the correct move is one more targeted verification of the disputed criterion, not a coin flip between them.
Where ContextQA fits in your RFP
ContextQA is built to win exactly the criteria this scorecard weights heavily. Tests are created in plain English on your application in minutes, which makes the live-demo question above an easy yes. Coverage spans web, mobile, API, and the enterprise systems most RFPs name: SAP, Salesforce, and legacy internal apps. Enterprise AI testing platform requirements like SOC 2 Type II and SSO are standard. Agent-specific depth covers guardrails, tool-call validation, and model-drift regression natively, and exportable test code answers the exit question in writing. Put us in your test automation RFP shortlist and book a demo with your hardest application; the live-build test in question one is the fastest way to score us honestly.
The bottom line
A test automation RFP succeeds or fails before responses arrive, in the requirements you write and the rubric you lock. Write requirements from your real failures, weight the four criteria where AI vendors genuinely differ, demand numbers in writing including pricing, and reserve final judgment for a bake-off on your own application. The vendors who resist that process are answering your most important question early.
Sources
- Responsive: RFP evaluation criteria and scoring guidance. Typical enterprise weighting practice.
- AICPA: System and Organization Controls (SOC) framework. The standard behind SOC 2 requirements.
- Cloud Security Alliance: AI Safety working group. Security evaluation vocabulary for AI vendors.