TL;DR: Most software pilots fail before they start. MIT’s Project NANDA found that 95 percent of generative AI pilots deliver no measurable P&L return, and the cause is rarely the technology: it is pilots run without pass criteria, on toy applications, by vendor engineers. This guide is the complete test automation POC framework: who to involve, the 30-day week-by-week plan, the exit criteria that force an honest decision, and the failure patterns to design out on day zero.
Last updated: July 4, 2026
Quick answers
What is a test automation POC? A time-boxed trial, usually 2 to 4 weeks, where a shortlisted tool is proven against your real applications, by your own team, against pass criteria written before the trial starts. It answers one question: does this tool work on our stack, at our skill level, under our release pressure?
How long should a test automation POC take? 30 days is the sweet spot: long enough to survive one real UI change and one release cycle, short enough to hold the team’s attention. Two weeks is the honest minimum, and anything past six weeks is a stalled decision wearing a trial as camouflage.
What are good POC success criteria? Four measurable ones: automation time per flow, the percentage of tests that survive a real UI change untouched, the quality of failure diagnostics when something breaks, and whether your team did the work without vendor hand-holding. Write the pass thresholds down before day one.

Why do most pilots fail?
The failure statistics are brutal and public. Alongside MIT’s 95 percent finding, the RAND Corporation’s research puts the failure rate of AI projects above 80 percent, roughly double the rate of ordinary IT projects, and its interviews with practitioners land on the same root causes every time: unclear success definitions, chasing technology instead of outcomes, and evaluations disconnected from real workflows.
Translate that to testing tools and the pattern is recognizable. The vendor runs a polished demo on their sample app. Everyone nods. A trial license appears, gets used for a week on low-stakes flows by whoever had spare time, and quietly expires. Six months later nobody can say what was learned, and the team runs another pilot with another vendor. A test automation POC exists to break exactly this loop, and it breaks it with structure, not enthusiasm.
What is a test automation POC and when do you actually need one?
A test automation POC is a decision instrument, not a tryout. The distinction is exit criteria: a tryout ends with opinions, a POC ends with a go or no-go memo backed by numbers.
You need one when the decision is expensive to reverse: replacing a legacy suite, standardizing a multi-team platform, or committing annual budget. You do not need one for a single team adopting a free framework; a two-day spike answers that. And you should refuse to run one before the paper evaluation is done: a POC tests the finalist, not the field. Shortlisting belongs to the buyer’s guide stage, with its 12 qualifying questions, so the expensive trial capacity is spent on at most two credible candidates.
Who should run the test automation POC?
Your team. That sentence removes half the failure modes on its own.
The lead: the QA engineer or SDET who will own the tool in production, not the most senior person available. The skeptic: one engineer who prefers the current stack, assigned to find real weaknesses; converted skeptics are how rollouts succeed later. The developer: one dev who will consume test results in CI, because a tool developers ignore is shelfware with a dashboard. The sponsor: whoever owns the budget reviews the gates weekly, 30 minutes, no more.
The vendor’s role is support, not labor. If vendor engineers write your pilot tests, you learn their skill level, not the product’s. The one exception: watching a vendor engineer handle YOUR hardest flow live in week one is useful calibration, once, with your team driving afterward.
The 30-day test automation POC framework
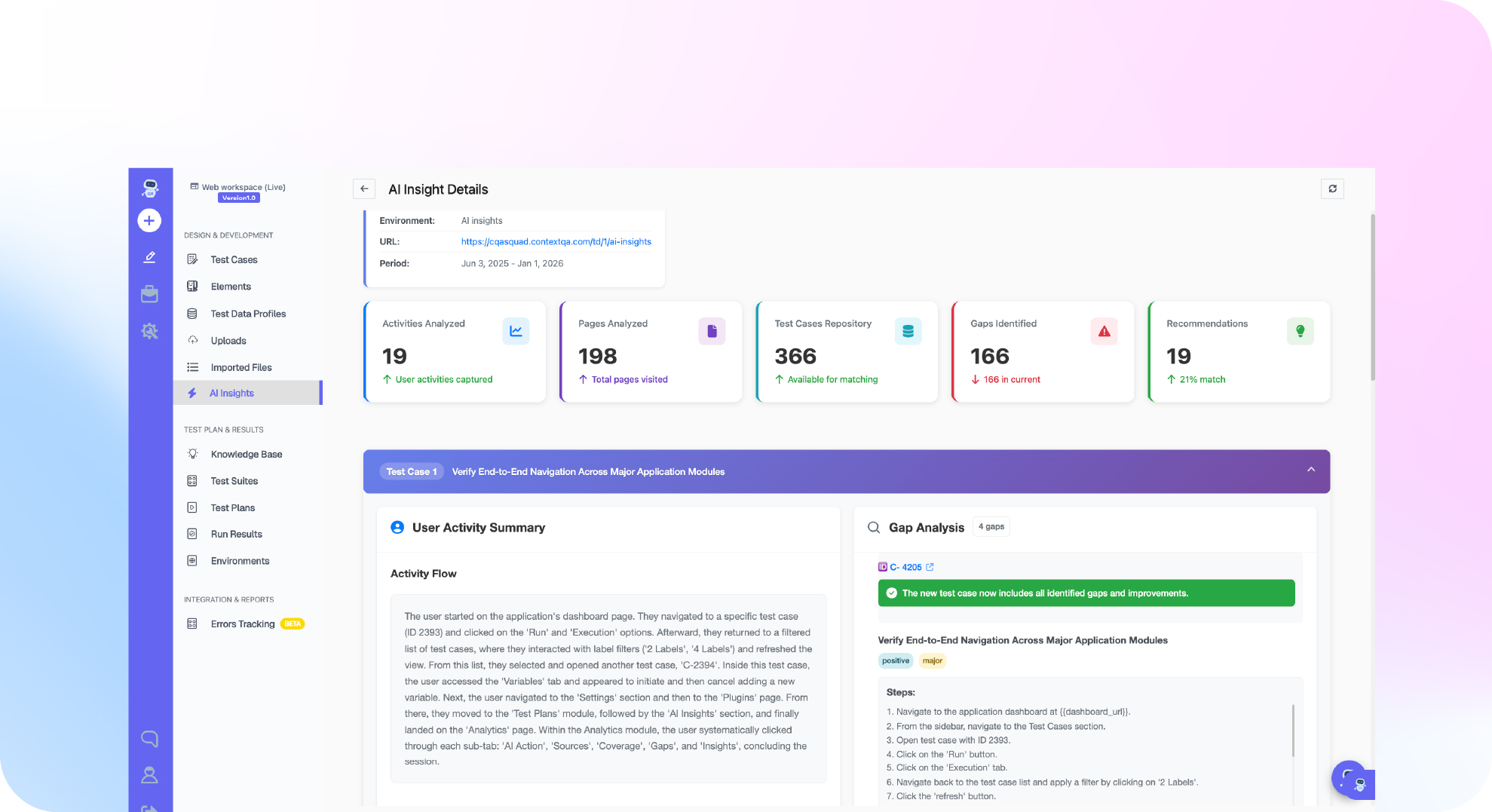
Before week one there is a week zero: pick the 10 flows, write the exit criteria, and agree the scorecard with the sponsor. Ten flows is deliberate: enough to expose patterns, few enough to finish. Choose them by revenue risk and technical variety, and include your two ugliest, the ones with iframes, dynamic tables, or a legacy system underneath, because a tool that only handles your easy flows answers a question nobody asked.
Week three deserves emphasis because almost nobody does it: break things on purpose. Ship a real UI change, rename fields, restructure a form, and measure the survival rate. This single week converts self-healing from a slide claim into a percentage. Track triage time too: when a test fails, how long until an engineer knows whether the app or the test broke? Diagnostic quality is the difference between flaky-test hell and a suite people trust.
What exit criteria should a test automation POC have?
Four metrics, with thresholds written in week zero. Numbers below are sensible defaults to argue with, not universal truths.
Automation time per flow: median under 2 hours per flow for an AI-native tool, under a day for a code framework your team already knows. Change survival: at least 70 percent of tests survive a real UI change untouched or self-healed. Diagnostic quality: under 10 minutes median to root-cause a failure, measured on real failures from week three. Team independence: 100 percent of flows automated by your engineers after the week-one calibration session.
Add one qualitative gate: would the skeptic ship it? Write their verdict, verbatim, into the final memo. And hold the line on validation versus verification: the POC verifies the tool works; the memo validates it solves your actual problem. Tools pass POCs and still fail teams when those two get conflated.
Which flows should you pilot first?
Rank your candidate flows on two axes: business damage if broken, and historical breakage frequency. The top-right corner is your pilot set. In practice that means checkout and payment paths for commerce, quote-to-cash for B2B, claims or onboarding for regulated industries, and always, always the flow that crosses into your enterprise systems. If your revenue path touches SAP or Salesforce, a test automation POC that avoids them is theater; put the enterprise-grade requirements in the pilot where they can fail early and cheaply.
Which mistakes kill test automation POCs?
No week zero. Starting the clock without written criteria converts the POC into a vibe check. Every later argument about the verdict traces back to this omission.
The demo app trap. Any evaluation not run on your own application measures marketing, not software.
Too many vendors. Three simultaneous POCs get a third of the attention each and produce three shallow verdicts. Two finalists, sequential if capacity is tight.
Letting it drift. A POC without a hard end date becomes ambient tooling nobody owns. The 30-day box with weekly gates exists to force the decision the trial was funded to produce.
Testing only the happy path. Week three exists because production is not a happy path. A tool never stressed during the trial will be stressed for the first time during a release.
What should week zero actually produce?
Week zero ends with four artifacts in a shared document, and the POC does not start until all four exist.
The flow list: ten flows with owners, ranked by revenue risk, ugliest two marked. The scorecard: the four exit criteria with thresholds and how each will be measured. The calendar: four weekly 30-minute gate reviews booked with the sponsor before the trial begins, because meetings scheduled later get scheduled never. The decision rule: one sentence stating what happens on pass and on fail, signed by the budget owner. “If 3 of 4 gates pass we negotiate a contract in week five; if not, we run finalist two” is a decision rule. “We will see how it goes” is how 95 percent becomes your number too.
Week zero costs about six working hours. It is the highest-return six hours in the entire evaluation, and its absence is detectable in every failed pilot postmortem.
How do you compare two finalists fairly?
Same ten flows, same exit criteria, same team, and ideally sequential rather than parallel: two weeks each with the same engineers produces cleaner signal than four weeks of split attention. Sequence the incumbent-style candidate first if one exists, because your team’s learning curve flatters whoever goes second, and you want that bias working against the incumbent, not for it.
Normalize the one thing you cannot equalize: vendor responsiveness. Log every support touch during each trial, count and latency, because trial-week support is the best support you will ever receive and the difference between vendors at their best predicts the difference at their normal. Then put both scorecards side by side in the go or no-go memo and let the floors, not the totals, frame the recommendation. A 78 that passed every floor beats an 84 that failed enterprise coverage, every time.
What happens after a successful test automation POC?
The pilot proved ten flows; production needs hundreds. The rollout sequence that preserves POC momentum: first, negotiate with your POC data, because measured automation time and survival rates are pricing arguments no vendor can hand-wave. Second, convert the pilot flows into the production seed suite rather than starting fresh; the trial work was real work.
Third, expand app by app, not team by team, keeping each application’s flow owners doing the automation so knowledge stays where the risk lives. Fourth, set the 90-day metric review: the same four exit criteria, remeasured at scale, become your ongoing health check. A POC that ends with a signed contract is a success; one that ends with a repeatable operating rhythm is a strategy. The gap between those two outcomes is roughly one quarter of deliberate follow-through, and it is where the shift-left ambitions either materialize or quietly expire.
The copy-paste week-zero scorecard
Steal this directly into your shared document and argue about the thresholds, which is the point.
Gate 1, speed: median authoring time per flow. Threshold: under 2 hours AI-native, under 1 day code-based. Measured by: timestamped log per flow, kept by whoever automated it. Gate 2, resilience: percent of tests surviving one real UI change untouched or auto-healed. Threshold: 70 percent. Measured by: week-three breakage run against the release branch. Gate 3, diagnosability: median minutes from failure notification to root cause identified. Threshold: 10 minutes. Measured by: the three real failures you will inevitably collect. Gate 4, independence: percent of flows automated by your team without vendor hands on keyboard. Threshold: 100 percent after the single calibration session.
Add the two qualitative lines that keep the memo honest: the skeptic’s verdict, quoted verbatim, and the developer’s answer to “would you trust this in the merge pipeline?” Neither has a threshold; both have veto weight in the reconciliation meeting.
Finally, write the decision rule under the table before day one: what specifically happens on pass, on partial pass, and on fail, with a name attached to each branch. This paragraph is the difference between a test automation POC and an expensive month of opinions.
How do you POC AI agent testing specifically?
If the product under test includes an AI agent or LLM feature, the standard ten-flow structure needs three additions, because agent failures do not look like UI failures.
Add adversarial flows to the ten. At least two of your pilot flows should be attack-shaped: a prompt-injection attempt against the agent, and a request that should trigger a refusal. The evaluation question is whether the platform can express and assert these at all, since most UI-era tools have no vocabulary for them.
Test the tool-call layer, not the chat text. Have the platform assert on which function the agent invoked and with what arguments, not just the final message. In week three, alongside the UI breakage test, swap or update the underlying model if you can, and measure which agent tests catch the behavioral drift. That single exercise separates platforms that test agents from platforms that screenshot chat windows.
Score consistency handling. Agents are non-deterministic; run the same agent flow twenty times and examine how the platform reports the variance. A tool that renders ten subtly different transcripts as ten unrelated results will bury your team in false alarms by month two. The platforms built for this express pass criteria as policies, tone, safety, task completion, rather than string equality, and the difference is visible within one POC afternoon.
What instrumentation does the POC itself need?
The framework lives or dies on measurement, and measurement needs about an hour of setup before day one.
The flow log: a shared sheet with one row per flow: owner, start timestamp, finish timestamp, blockers hit, vendor touches required. Filled in as work happens, not reconstructed on Friday, because reconstructed timings flatter everyone.
The breakage branch: week three’s UI change prepared in advance by a developer, realistic in scope, one renamed field, one restructured component, one moved button, and held unmerged until the scheduled day. Improvised breakage tests turn into softballs.
The failure journal: every red result during the month gets three fields: when noticed, when root-caused, verdict (app bug, test issue, environment). This journal becomes gate three’s data and, as a bonus, an honest preview of the triage life your team is buying.
The touchpoint counter: every vendor interaction logged with latency. Not for blame, for prediction: trial-month support is the ceiling, and the gap between finalists at their ceiling is the gap you will live with at their floor.
None of this is heavyweight; all of it fits in one spreadsheet with four tabs. The teams that skip it still form opinions, but they cannot defend them in the reconciliation meeting, and undefendable opinions are how a test automation POC quietly reverts to a vibe check.
More questions teams ask about test automation POCs
What is the difference between a POC, a pilot, and a trial? A trial is vendor-granted access with no structure. A test automation POC proves the tool works on your stack against written criteria. A pilot is the step after: the chosen tool running in one team’s real release process before organization-wide rollout. Teams that treat these as one blurry phase get the 95 percent outcome; teams that sequence them get compounding evidence.
Should you ever pay for a POC? For a 30-day evaluation of a SaaS testing platform, no; vendor-side cost is low and free evaluation is table stakes. The exception is heavy enterprise integration work, on-premise setups or custom system connectors, where a paid, scoped POC with credit against the contract is a fair structure that filters unserious buyers and unserious vendors alike.
What if both finalists pass every gate? A good problem with a concrete tiebreak order: diagnostic quality on week-three failures first, because it predicts daily life; team preference second, because adoption is destiny; commercial terms third, including the exit clause. Never tiebreak on roadmap promises, and never split the estate by adopting both, which doubles every integration and training cost for years.
How much team time does a test automation POC really take? Budget the lead at half time for the month, the skeptic and developer at a few hours per week, and the sponsor at 30 minutes weekly. That is roughly 100 to 120 person-hours total, and it is the correctly-sized insurance premium on a six-figure, multi-year tooling decision.
Running your POC on ContextQA
We designed our evaluation experience around this exact framework, because structured POCs favor tools that work. Week one on ContextQA typically means your 3 starter flows automated in plain English within the first session, by your team. Week two’s hard flows are where enterprise coverage earns its scorecard weight, and week three’s survival test is the one we most want you to run, since self-healing is measurable, not claimable. Our structured pilot program packages the 30-day plan, gates included, and booking a demo with your ugliest flow is the fastest week-zero you can run.
The bottom line
The public failure numbers are not an argument against pilots; they are an argument against unstructured ones. A test automation POC with ten real flows, four written exit criteria, your own team driving, and a deliberate breakage week produces the one thing most evaluations never deliver: a decision you will still defend in a year. Write the criteria first. Everything else follows from that.
Sources
- Fortune: MIT report finds 95% of generative AI pilots failing. MIT Project NANDA findings, August 2025.
- RAND Corporation: The Root Causes of Failure for Artificial Intelligence Projects. The 80 percent failure finding and practitioner root causes.