TL;DR
- AI now writes a large share of production code, but it is not safe by default. Independent 2025 research links AI assistants to more duplication, more rework, and more security defects.
- Reviewing AI code is not the same as reviewing human code. There is no author intent to question, and the code often looks correct while hiding edge-case and security gaps.
- Ship safely with two gates: a structured review before you merge, then layered testing before you release.
- AI agents make that review-and-test loop continuous and affordable, which is the only way to keep up with the pace AI generates code.
Quick Answer: Is AI-generated code safe to ship?
AI-generated code is not automatically safe to ship. Studies from 2025 found that AI assistants increase code duplication and rework, introduce more security weaknesses, and make even experienced developers slower while feeling faster. To ship it safely, treat every AI suggestion as an untrusted draft. Review it against the original requirement and a security checklist before you merge, then test it in layers (static analysis, unit, integration, and production monitoring) before you release. The goal is not to reject AI code. It is to verify it.
How we approached this guide
We pulled the most recent independent research on AI-generated code quality and security, then mapped it to the review and testing workflow we run inside ContextQA every day. This is not a list of opinions. Every claim below is tied to a 2024 or 2025 study from a research firm, an academic group, or a primary engineering source. For the deep, layer-by-layer testing playbook, this guide links out to our companion piece, How to Test AI Generated Code: A QA Checklist for 2026, so the two work together instead of repeating each other.
Is AI-generated code safe to ship? What the 2025 data says
The honest answer is that AI code is fast but not trustworthy by default. Three findings make the case clearly.
Quality is sliding. GitClear analyzed 211 million changed lines of code and found that copy-pasted, cloned lines rose from 8.3 percent in 2020 to 12.3 percent in 2024. For the first time, within-commit copy-paste exceeded the number of moved lines, and the share of code that was refactored and reused fell below 10 percent. In plain terms, AI is great at adding new code and poor at reusing existing code, which quietly inflates duplication and technical debt (GitClear, 2025).
Speed is an illusion you have to verify. A controlled study by METR had experienced open-source developers complete real tasks with and without AI. They were 19 percent slower with AI, yet they believed AI had made them about 20 percent faster. That perception gap is the real risk. Teams that feel fast review their AI code less carefully, which is exactly when defects slip through (METR, 2025).
The team-level tradeoff is real. Google’s DORA program surveyed more than 39,000 professionals and found that 75.9 percent of developers now use AI for daily tasks. AI lifted individual productivity and job satisfaction, but at the team level it was associated with a measurable drop in software delivery stability and throughput. Individual speed does not equal shipping quality (DORA, 2024).
Security is the sharpest edge. Academic work on secure coding with large language models shows that AI frequently produces code containing common weaknesses unless it is explicitly prompted and checked for security (arXiv, 2025). The usual suspects are the same ones on the OWASP Top 10, including injection and cross-site scripting (CWE-79). AI does not know your threat model. It pattern-matches to whatever was common in its training data, secure or not.
There is also a newer risk that pure testing can miss. AI tends to invent plausible package names, and attackers now register those exact fake names so that a single hallucinated import pulls in malicious code. That is a supply-chain problem you catch in review, not in a unit test, which is one more reason review and testing have to work together rather than as substitutes.
Put those together and the picture is consistent. AI helps you write more code faster, and it raises the odds that the code is duplicated, insecure, or subtly wrong. The cost of catching that late is well documented, and it climbs the further the defect travels, as we cover in the real cost of defects in software testing.
Why reviewing AI code is different from reviewing human code
A normal code review assumes a human author with intent. You can ask why a choice was made. AI removes that author. The code arrives with no reasoning you can interrogate, and it tends to fail in ways human code rarely does.
- It is plausible, not correct. AI optimizes for code that looks right. A reviewer skimming for syntax will pass it. The bug lives in the edge case that was never in the prompt.
- It invents things confidently. AI will call functions, flags, or libraries that do not exist, with total confidence and clean formatting.
- It copies instead of reusing. As the GitClear data shows, AI pastes a fresh version rather than calling your existing helper, so duplication grows and one fix now needs five.
- It causes reviewer fatigue. When AI generates ten times more diffs, human reviewers rubber-stamp them. Volume defeats attention.
This is why a review of AI code has to be structured and partly automated. You cannot eyeball your way through code your tools wrote faster than you can read.
What vibe coding means for your QA process
Vibe coding is the practice of building software by describing what you want in natural language and accepting whatever the AI produces, often without reading it closely. It is fast and it ships real products, but it inverts the usual safety net. In traditional development the person who writes the code understands it. In vibe coding, nobody on the team may fully understand what shipped. That makes review and testing the only thing standing between a working demo and a production incident. If your team vibe codes, the rule is simple: the less a human wrote the code, the more rigorously a machine has to verify it. Everything in this guide applies double to code no human has read line by line.
The AI code review workflow (before you merge)
Run this as a gate on every AI-assisted pull request. It takes minutes and it catches the failures that testing alone misses.
1. Restate the requirement
Before reading a single line, write the one sentence the code is supposed to satisfy. AI optimizes for the prompt it received, not the outcome you wanted. If the diff does not map to that sentence, stop.
2. Read for intent, not syntax
Trace the logic against real inputs, especially the empty, the huge, and the malformed. AI handles the happy path well. It is the boundaries where it guesses.
3. Verify every API and dependency exists
Confirm that each function, parameter, and imported package is real and current. Hallucinated dependencies are also a supply-chain risk, because attackers register the fake package names AI tends to invent.
4. Run a security pass
Check the diff against the OWASP categories that matter for your app: injection, cross-site scripting, broken access control, and secrets in code. Pair the manual pass with automated security testing so nothing depends on a tired reviewer.
5. Check for duplication and refactor debt
Ask whether this logic already exists in the codebase. If AI re-implemented something you already have, replace the paste with a call to the existing function before it multiplies.
6. Add an adversarial AI review
Have a second model review the first model’s output with one instruction: find what is wrong. Models that generate confidently will critique sharply when asked to. GitHub documents this review-the-AI pattern as a core practice for AI-assisted code (GitHub Docs). When something does slip through, fast root cause analysis turns the failure into a fix instead of a mystery.
After the review: verify AI code with layered testing
Review catches intent and security problems. Testing proves the code behaves under real conditions. Use both. This guide stays focused on the review-and-safety side, so for the complete, layer-by-layer testing playbook (coverage thresholds, tooling, and the full checklist) follow our dedicated companion guide, How to Test AI Generated Code: A QA Checklist for 2026. The condensed model below shows where each layer fits.
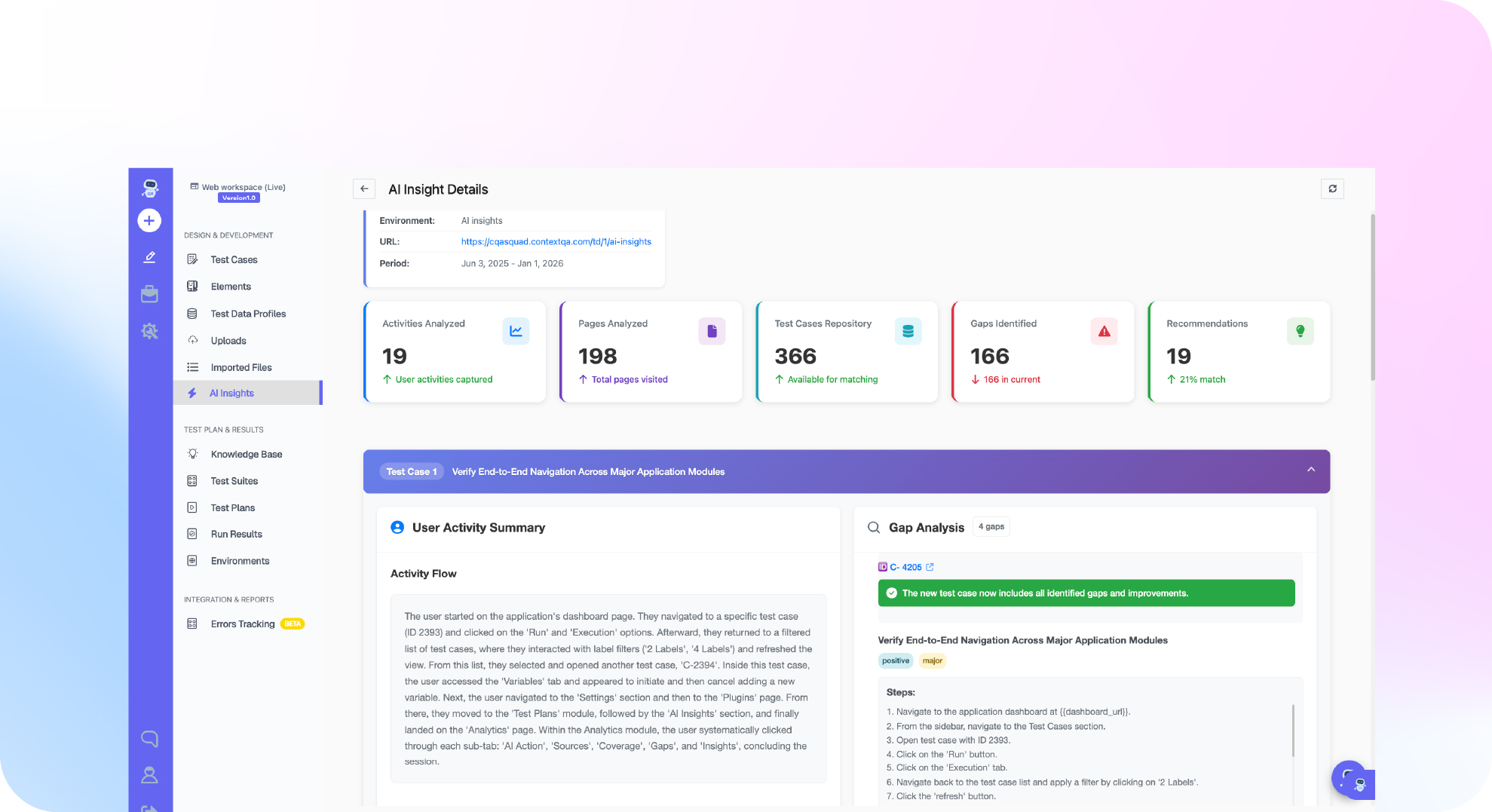
| Layer | What it catches in AI code | How to run it |
|---|---|---|
| Static analysis | Security smells, dead code, style drift | Linters and SAST on every commit |
| Unit tests | Wrong logic and missed edge cases | Tests written by a human or a second model, not the author model |
| Integration and E2E | Real behavior across the app, not just one function | AI agents that test from real application behavior |
| Security testing | OWASP risks the review missed | Automated security testing |
| Production monitoring | Regressions and drift after release | Continuous checks plus root cause analysis |
One rule matters most here. Do not let the model that wrote the code also write its tests. It will encode the same wrong assumption into both, and the suite will pass while the behavior is broken. This is the same loop logic behind shift-left and shift-right testing: prevent what you can early, and watch what you cannot in production.
If the AI-generated code powers a non-deterministic feature, where the same input can return a different output each run, fixed assertions will not work. Verify behavior and ranges instead of exact strings. Does the output stay within acceptable bounds, does it avoid forbidden content, does it stay consistent enough across runs. This is its own discipline, and it is becoming central to testing anything built on large language models.
A pre-ship safety checklist
- Write the one-sentence requirement the code must satisfy.
- Trace the logic against empty, large, and malformed inputs.
- Confirm every API, flag, and dependency is real and current.
- Scan the diff for injection, cross-site scripting, access control, and secrets.
- Replace duplicated logic with a call to existing code.
- Run a second model to find what is wrong.
- Run static analysis and unit tests written by someone other than the author model.
- Validate integration and end-to-end behavior in a real environment.
- Monitor production and feed every failure back into the test suite.
Common mistakes teams make with AI-generated code
Most AI code incidents trace back to a small set of avoidable habits.
- Letting the author model write its own tests. The suite passes because it encodes the same wrong assumption that produced the bug.
- Reviewing volume instead of risk. When AI generates ten diffs an hour, reviewers approve them to keep up. Gate the high-risk paths and automate the rest.
- Trusting green tests on non-deterministic features. A feature that returns a different answer each run cannot be checked with one fixed expectation.
- Skipping the security pass under deadline. That is exactly when injected and copied vulnerabilities ship.
- Treating duplication as harmless. Every pasted block is a future bug you now have to fix in many places at once.
Who owns the review, and how to scale it
Ownership is where good intentions fail. If review is everyone’s job, it is no one’s job. Make the author of the pull request responsible for running the six-step review and writing down the one-sentence requirement, and make a second person or a second model responsible for the adversarial pass. For high-risk areas such as authentication, payments, and data migrations, require a senior reviewer by policy, not by hope. Then scale the parts that do not need human judgment. Static analysis, security scanning, and end-to-end validation should run automatically on every AI-assisted pull request, so the human review starts from a clean signal instead of drowning in noise. The point is not to slow developers down. It is to move the boring, repeatable checks to machines so people spend their attention on the decisions only people can make.
How to know your AI code review is working
A process you cannot measure is a process you will quietly abandon under pressure. Track a few leading indicators so you can prove the gate is paying off. Watch your change failure rate and your rework rate, the two stability signals DORA ties directly to AI adoption. Watch the share of AI pull requests that fail the review gate before merge, because a healthy number is not zero. Watch your code duplication trend, since that is the clearest early signal of the maintainability debt the research measured. And watch how often a production failure maps back to AI-generated code, then feed each one into the test suite so the same class of bug cannot ship twice. If those numbers move the right way, the gate is working. If they do not, your review is theater.
Why AI agents make continuous review affordable in 2026
If AI writes ten times more code, humans cannot review and test all of it by hand. The answer is to fight AI volume with AI verification. This is the core idea behind agentic AI in software testing: agents that generate tests from real application behavior, run them across web, API, and mobile, and explain the failures.
In practice that means AI agents test the code as fast as AI writes it, self-healing keeps the suite green when the UI changes instead of breaking on every refactor, and code export keeps your tests portable so you are never locked in. The whole loop runs on one platform rather than five disconnected tools. That is how you keep review and testing continuous at AI speed instead of treating them as a bottleneck you skip under pressure.
Original proof: ContextQA for AI code validation
This is not theory for us. In partnership with IBM, ContextQA validated a migration of 5,000 test cases and eliminated flakiness across the migrated suite, which is exactly the kind of large, AI-accelerated change that breaks when it ships unverified (IBM case study). Verified users rate ContextQA 4.8 out of 5 for no-code AI test automation and auto-healing (G2 reviews). The pattern that works is consistent: let AI move fast on generation, and put an equally fast AI verification layer in front of production.
Limitations: when review and testing are not enough
Be honest about the edges. A review-and-test gate cannot fix a bad architecture or a vague requirement, and it will not catch a logic error that is also wrong in your specification. It does not remove the need for human judgment on high-risk changes such as auth, payments, and data migrations, which still deserve a senior set of eyes. And no amount of testing makes a non-deterministic AI feature behave deterministically. For those, you verify ranges and behaviors rather than exact outputs. The gate lowers risk dramatically. It does not make AI code risk-free.
Do this now
- Adopt the rule that every AI suggestion is an untrusted draft until reviewed and tested.
- Add the six-step review as a required gate on AI-assisted pull requests.
- Separate the author model from the model or person that writes the tests.
- Automate static analysis, security checks, and end-to-end validation so quality does not depend on reviewer energy.
- Feed every production failure back into the suite so the same bug cannot ship twice.
The bottom line
AI-generated code is not safe or unsafe on its own. It is unverified. The teams that win with AI are not the ones that generate the most code. They are the ones that review and test it as fast as they create it. Build the two gates, automate the heavy lifting with AI agents, and you get the speed of AI without inheriting its defects. That is the entire argument for a context-aware approach to quality, which is why ContextQA exists. When you are ready to put an AI verification layer in front of your AI code, book a demo.